- Build a webcrawler in julia.
- Use the data for a simple plot.
- find good selector
- extract content
- parse/collect details
Alien Facehugger Wasps, a Pandemic, Webcrawlers and Julia

TL;DR
Motivation
The web is full of interesting bits and pieces of information. Maybe it’s the current weather, stock prices, or the wikipedia article about the wasp that goes all alien parasite facehugger on other insects, which you vaguely remember from one of those late night documentaries (already sorry you are reading this?).
If you are lucky, that data is available via an API, making it usually pretty easy (not always tho, if API developers come up with byzantine authentications, required headers or other elegant/horrible designs, the fun is over) to get to the data.
A lot of the shiny nuggets are not available via a nice API, tho. Which means, we have to crawl webpages. Pick something that you are really interested in / want to use for a project of yours, that’ll make it less of a chore and far more interesting!
Local = Relevant
For me, currently, that’s the Covid-19 pandemic. And more specifically, how it is developing close to me. In my case, that means the city of Hamburg in Germany.
Chances are, these specific numbers/case is not relevant to you. But that’s a good thing, you can use what you learned here and mine the website of your home city maybe (or whatever you are interested in).
Nothing helps your brain absorb new things better than generalizing those new skills and using them to solve related problems! There is the official website of the city, that has a page for the covid-19 numbers, hamburg.de.
The page with the numbers is in german, but don’t worry, that’s what our webcrawler will hopefully help us with — we can get to the numbers without having to understand all the surrounding text. I will try to help out and translate what is relevant, but that will only be a minor detail when we try to find the right text to extract from.
If you like, you can check out the notebook or even code along in binder.
First, let’s get some of the dependencies out of the way:
Aside from HTTP.jl to request the website, we will also use Gumbo to parse html and Cascadia to extract data from the html document via selectors.
using HTTP
using Gumbo, Cascadia
using Cascadia:matchFirst
We need to fetch and parse the website, which is easily done with Gumbo.
url = "https://www.hamburg.de/corona-zahlen"
response = HTTP.get(url)
html = parsehtml(String(response))
# =>
HTML Document:
<!DOCTYPE >
HTMLElement{:HTML}:<HTML lang="de">
<head></head>
<body class="no-ads">
HTTP/1.1 200 OK
ServerHost: apache/portal5
X-Frame-Options: SAMEORIGIN
# ...
Alright, we can now start to parse data from the html document, by using query selectors.
You know, they might actually be called css selectors, I don’t know. How precise is the frontend terminology anyways, right?
Oh look, a pack of wild frontenders! Hmm, what are they doing, are they encircling us? They do look kinda angry, don’t they? I guess they just tried to vertically align some div the whole day or something.
Ok… I guess we should leave now.
Seems important

We could start with the first information we see on the page, after all, there must hopefully be a reason that it is at the top of the page.
The three bullet points with the numbers mean confirmed cases, recovered and new cases. Now the trick is to find the best selectors. There are a few plugins for the different browsers that help finding the right selectors quickly.
But it is also pretty easy to do by hand. When right-click/inspecting an element on the page (this requires the developer tools) one can pretty quickly find a decently close selector.
If you want to test it out in the browser first, you can write something like this document.querySelectorAll(".c_chart.one .chart_legend li") in the browser console. Some browsers even highlight the element on the page when you hover over the array elements of the results.
Using the selectors in julia is pretty neat:
eachmatch(sel".c_chart.one .chart_legend li", html.root)
# =>
3-element Array{HTMLNode,1}:
HTMLElement{:li}:<li>
<span>...</span>
Bestätigte Fälle 5485
</li>
# ...
Ok, we need to extract the numbers from the text of each html element. Using a simple regex seems like the easiest solution in this case. Check this out, it looks very similar to the previous selector matching:
match(r"\d+", "Neuinfektionen 25")
# =>
RegexMatch("25")
Nice, huh? Ok, but we only need the actual match.
match(r"\d+", "Neuinfektionen 25").match
# =>
"25"
And we need to cast it to a number:
parse(Int, match(r"\d+", "Neuinfektionen 25").match)
# =>
25
We want to do this for each element now, so we extract the text from the second node (the span element is the first, see the elements above).
Then we do all the previously done matching and casting and we got our numbers!
function parsenumbers(el)
text = el[2].text
parse(Int, match(r"\d+", text).match)
end
map(parsenumbers,
eachmatch(sel".c_chart.one .chart_legend li", html.root))
# =>
3-element Array{Int64,1}:
5485
5000
25
Learning how to Date in german
We should also extract the date when those numbers were published. The selector for the date on the page is very easy this time: .chart_publication.
In the end we want some numbers, that we can use to instantiate a Date object, something like this Date(year, month, day).
We are starting out with this, however:
date = matchFirst(sel".chart_publication", html.root)[1].text
# =>
"Stand: Mittwoch, 5. August 2020"
Oh dear, it’s in german again. We need "5. August 2020" from this string.
parts = match(r"(\d+)\.\s*(\S+)\s*(\d{4})", date).captures
# =>
3-element Array{Union{Nothing, SubString{String}},1}:
"5"
"August"
"2020"
Better, but it’s still in german!
Ok, last bit of german lesson, promised, how about we collect all the month names in a tuple?
Then we can find its index in the tuple. That would be the perfect input for our Date constructor.
const MONTHS = ("januar", "februar", "märz", "april",
"mai", "juni", "juli", "august",
"september", "oktober", "november", "dezember")
findfirst(m -> m == lowercase(parts[2]), MONTHS) # => 8
using Dates
Date(parse(Int, parts[3]),
findfirst(m -> m == lowercase(parts[2]), MONTHS),
parse(Int, parts[1]))
# => 2020-08-05
More local = more relevant!
There are a few more interesting nuggets of information, I think the hospitalization metrics would be very interesting, especially to investigate the correlation between when cases are confirmed and the delayed hospitalizations.
But one thing that is especially interesting (and I don’t think such locally detailed information is available anywhere else) are the number of cases in the last 14 days, for each borough.
Speaking of local, this is probably the most local we can get.
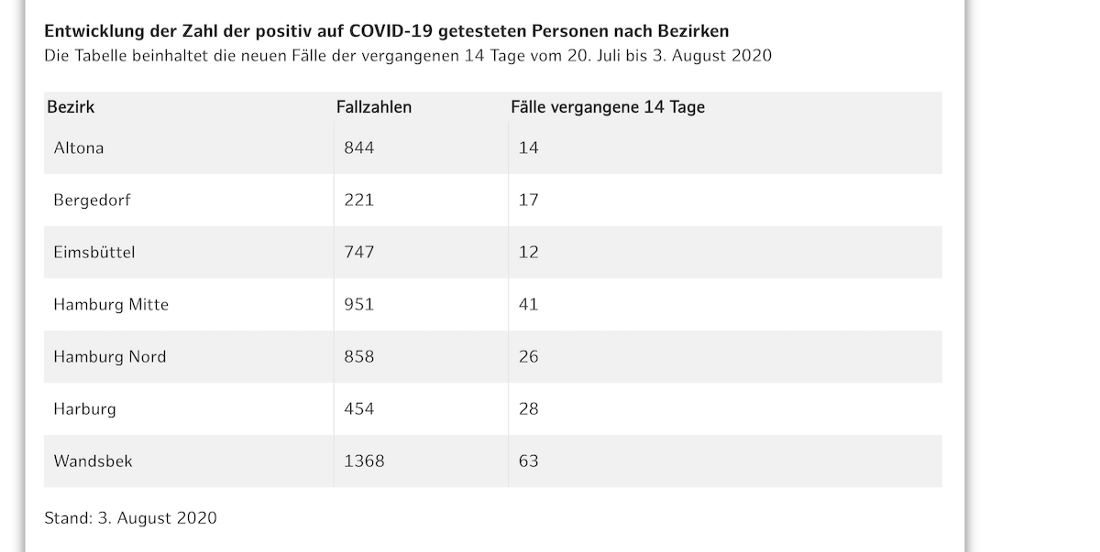
By now, you probably start to see a pattern:
rows = eachmatch(sel".table-article tr", html.root)[17:end]
df = Dict()
foreach(rows) do row
name = matchFirst(sel"td:first-child", row)[1].text
num = parse(Int, matchFirst(sel"td:last-child", row)[1].text)
df[name] = num
end
df
# =>
Dict{Any,Any} with 7 entries:
"Bergedorf" => 17
"Harburg" => 28
"Hamburg Nord" => 26
"Wandsbek" => 63
"Altona" => 14
"Eimsbüttel" => 12
"Hamburg Mitte" => 41
Great, that’s it?
No! No, now the real fun begins. Do something with the data! You will probably already have some idea what you want to do with the data.
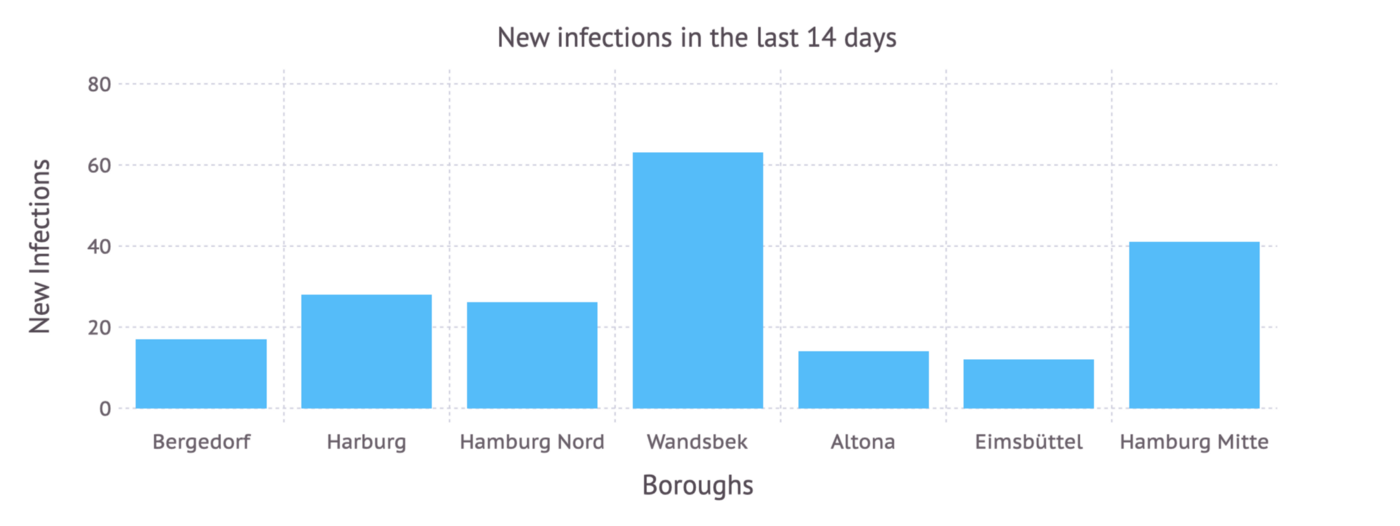
How about ending this with something visual?
Visualizations, even a simple plot, can help a lot with getting a feel for the structure of the data:
using Gadfly
Gadfly.set_default_plot_size(700px, 300px)
There are a lot of great plotting packages for julia, I personally really like Gadfly.jl for its beautiful plots.
plot(x=collect(keys(df)),
y=collect(values(df)),
Geom.bar,
Guide.xlabel("Boroughs"),
Guide.ylabel("New Infections"),
Guide.title("New infections in the last 14 days"),
Theme(bar_spacing=5mm))
The end, right?
Ha ha ha ha- nope. Webcrawlers are notoriously brittle, simply because the crawled websites tend to change over time. And with it, the selectors. It’s a good idea to test if everything works, once in a while, depending on how often you use your webcrawler.
Be prepared to maintain your webcrawler more often than other pieces of software.
A few things to check out
Very close to the topic: I created a little package, Hamburg.jl, that has a few datasets about Hamburg, including all the covid-19 related numbers that we scraped a little earlier.
The official julia docs should get you up and running with your local julia dev setup.
One last crawler
Ok, one more thing, before I let you off to mine the web for all its information:
html = parsehtml(String(HTTP.get("https://en.wikipedia.org/wiki/Emerald_cockroach_wasp")))
ptags = eachmatch(sel".mw-parser-output p", html.root)[8:9]
join(map(n -> nodeText(n), ptags))
# =>
"Once the host is incapacitated, the wasp proceeds to chew off half of each of
the roach's antennae, after which it carefully feeds from exuding
hemolymph.[2][3] The wasp, which is too small to carry the roach, then leads
the victim to the wasp's burrow, by pulling one of the roach's antennae in a
manner similar to a leash. In the burrow, the wasp will lay one or two white
eggs, about 2 mm long, between the roach's legs[3]. It then exits and proceeds
to fill in the burrow entrance with any surrounding debris, more to keep other
predators and competitors out than to keep the roach in.\nWith its escape
reflex disabled, the stung roach simply rests in the burrow as the wasp's egg
hatches after about 3 days. The hatched larva lives and feeds for 4–5 days on
the roach, then chews its way into its abdomen and proceeds to live as an
endoparasitoid[4]. Over a period of 8 days, the final-instar larva will consume
the roach's internal organs, finally killing its host, and enters the pupal
stage inside a cocoon in the roach's body.[4] Eventually, the fully grown wasp
emerges from the roach's body to begin its adult life. Development is faster in
the warm season.\n"
…the wasp proceeds to chew off half of each of the roach’s antennae, after which it carefully feeds from exuding…
…what…
…The hatched larva lives and feeds for 4–5 days on the roach, then chews its way into its abdomen…
…the…
…Over a period of 8 days, the final-instar larva will consume the roach’s internal organs, finally killing its host…
…hell mother nature, what the hell…